近日,中国科学院合肥物质科学研究院健康所李海研究员团队在决策元控制的计算建模研究中取得关键性进展。相关研究成果发表在认知神经科学的专业期刊Journal of Cognitive Neuroscience (JoCN) 上。
在日常生活中,人们经常需要完成一系列决策以实现最终目标。例如,在选择餐厅时,我们首先决定目的地和路线,而就餐后的体验会影响我们对餐厅的喜爱程度,进而决定下一次的选择偏好。然而,个体在进行此类序贯决策时表现出显著差异:有些人倾向于依赖习惯,选择熟悉的选项;而另一些人则更灵活,会根据当前信息和目标动态调整选择;更多的人则介于两者之间。那么,习惯性和计划性在序贯决策行为中的比重是如何决定的?这一问题是认知神经科学领域中的关键挑战之一,即决策元控制中的仲裁机制。
通过行为实验和计算建模的方法,该研究揭示了:个体决策中习惯性策略(无模型强化学习,model-free reinforcement learning)与目的性策略(基于模型的强化学习,model-based reinforcement learning)的权重由可用的工作记忆资源决定。研究团队提出了一种新型混合强化学习模型(Hybrid-WM reinforcement learning model),将工作记忆资源的有限性纳入决策机制的计算框架中。相较于传统强化学习模型,该模型不仅能够成功模拟任务负荷和延迟时间对决策行为的经典影响,还能更精准地拟合实验数据。此外,该模型在独立验证数据集上的表现进一步支持其广泛适用性。
本研究量化了工作记忆资源有限性在决策元控制中的核心作用及计算机制,为理解序贯决策行为提供了全新视角。这一发现不仅对认知科学基础研究具有重要意义,还为人机交互领域的创新应用带来启发。此外,提出的混合强化学习模型为计算精神病学提供了新工具,有助于深入解析认知障碍、精神障碍及神经疾病患者在元控制机制中的缺陷,进而为制定更精准的诊断和干预策略提供理论依据。
该论文的第一作者为健康所硕士研究生左肇煜,通讯作者是李海研究员和杨立状副研究员。本研究得到了国家自然科学基金、安徽省自然科学基金的支持。
文章链接:https://doi.org/10.1162/jocn_a_02237
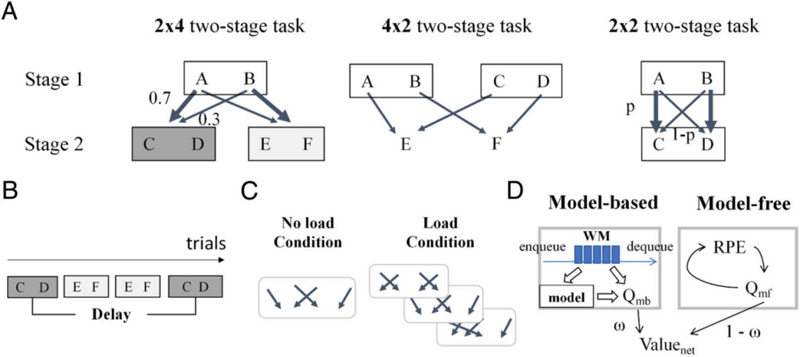
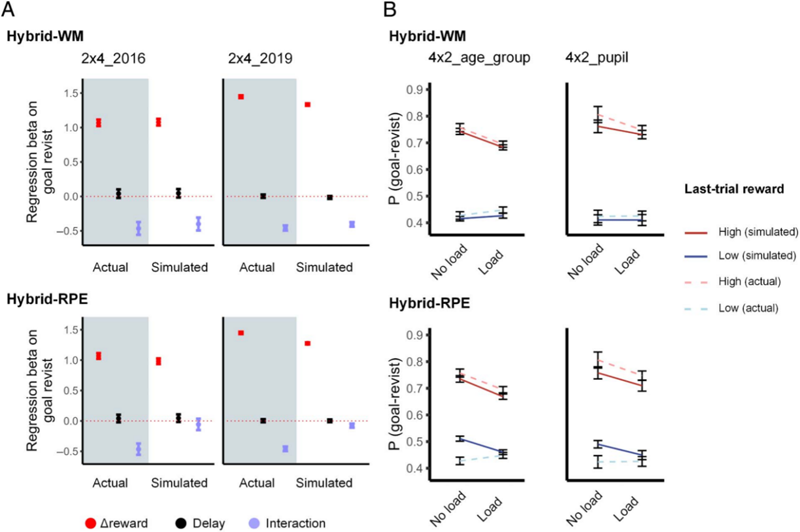
计算机制原理图




